Info
- Doebel: https://publish.obsidian.md/ddoebel/Welcome
- Dragos: https://polybox.ethz.ch/index.php/s/jgGpEyX6Ctf2KCD
- uploads faster than Popa
- Popa: https://polybox.ethz.ch/index.php/s/roTjs6ppjc5fXW3
- (outdated: https://n.ethz.ch/~iopopa/)
Übungen
#timestamp 2025-09-19
![[NumCSE_week1_practice.cpp]]
#timestamp 2025-10-03
why squared loss?
- differentiable
- always positive
- icreasesquadratically with distance
(-> but sth. oder would also be possible)
least square solution:
=>
=>
if matrix is sparse, we can introduce the residual
=>
#timestamp 2025-10-31
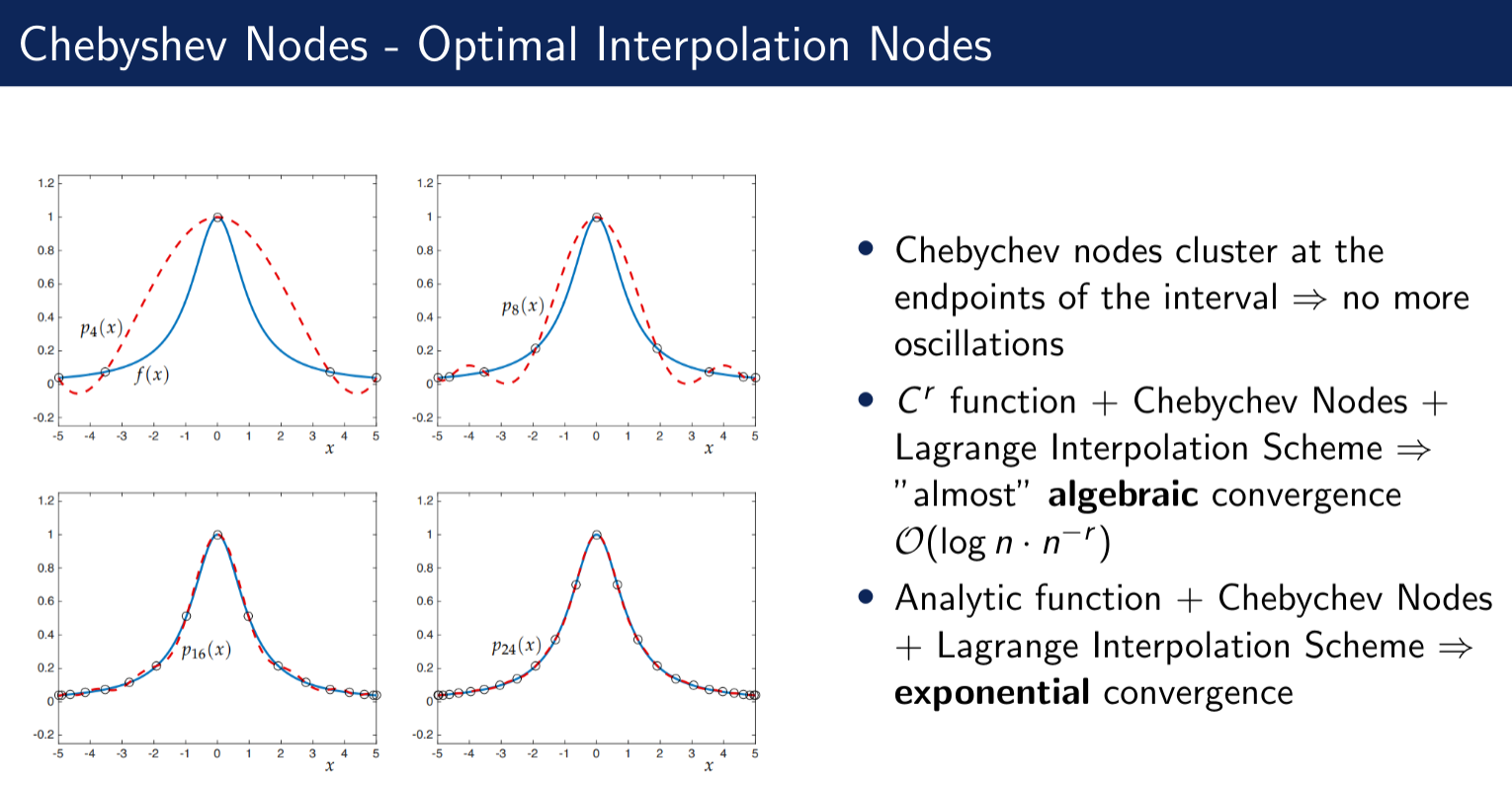
#timestamp 2025-11-29
do {
Eigen::Vector4d s = df(x).householderQr().solve(f(x));
x = x - s;
gn_update.push_back(s.norm());
// absolute stopping criteria
} while(gn_update.back() > tol);
Newton-Gauss method, see 8.11)d)
Hiptmair used
s.lpNorm<Eigen::Infinity>();
Infinity-norm stopping is better, because:
- it is cheaper to compute,
- it treats the largest component directly,
- it is less sensitive to cancellation.
He also used
df(x).colPivHouseholderQr().solve(f(x));
The Jacobian in Gauss–Newton can easily become nearly rank-deficient, especially early in the iteration.
Without pivoting, householderQr() may produce an unstable or unusable step. colPivHouseholderQr() safeguards the solve by reordering the columns so that the effective conditioning is improved.