everything on Moodle
- none
Vorlesung
#timestamp 2025-11-06
Lecture 8
logistic regression model (slide 45)
- line between dogs and cats has probability
number of hidden layers + size of each layer is mostly guessing + keeping what works
if you make all activations linear (
softmax-function: creates positive [0,1] numbers out of k data
-> exponential, because the derivative is nice + makes everything positive (but e.g. square would also work)
normally, you test multiple architectures and select the one that works best using the validation set
-> do not extrapolate well!
const functions are important and are difficult to choose
error signal:
derivative of loss to respect to a layer
like feature
-> error signal propagates backwards
-> that's why we don't have feedbacks: we would have infinite error loops
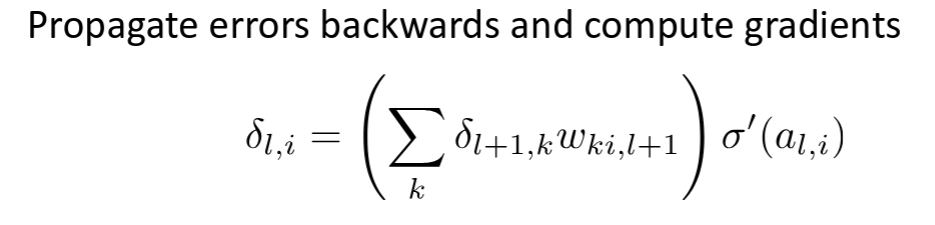
NOTE: the sigmoid function
leaky value
#timestamp 2025-11-13
Problems using MLPs with grid-like structure
depth of filter (channel?) is equal to number of channels in the previous layer (?)
-> there will be a question about convolutional layers (slide 39 / week 9)
#timestamp 2025-12-04
softmax returns probabilities (
DINO: better genarilzability than supervised models
#timestamp 2025-12-11
![[Lecture13_Generative_Models.pdf]]
#timestamp 2025-12-18
Grad-Cam: only have to compute gradient to see -> works for (nearly) all architectures
- only positive values kept because for negative values we either have to scale down positive (increase all other classes), which will be noise and not very useful
Concept Activation Vectors (sensitivity to concept)
- small product: change v_c -> will not change much -> model is not sensitive much to that concept
mock exams do not cover all material today !!
mostly contextual instead of mathematical (although this year, there might will be a math question)