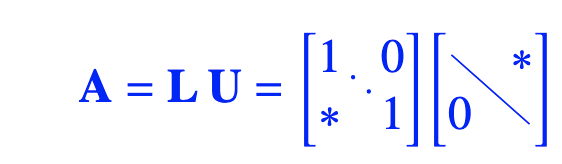Matrizen sollen nicht unter dem Bruchstrich geschrieben werden
Lineare Kombination
Standardbasis
Standardbasis von -dimensionalem Koordinatensystem bestehet aus Vektoren der Form:
Sie bilden die Identitätsmatrix
1.2 Gauss-elimination
Note
Die Eliminationsschritte machen nur lineare Kombinationen von Gleichungen
Protokollmatrix
Bildet die Operationen der Gauss-elimination ab. Ist am Anfang eine Diagonalmatrix.
Vertauschen zweier Zeilen:
In der Protokollmatrix werden die entsprechenden Zeilen vertauscht.
Multiplizieren einer Zeile mit :
Alle Elemente einer Zeile in der Protokollmatrix werden mit derselben Zahl multipliziert.
Addieren eines Vielfachen einer Zeile zu einer anderen Zeile:
Die entsprechende Zeile in der Protokollmatrix wird durch die Summe der ursprünglichen Zeile und dem Vielfachen der anderen Zeile ersetzt. ( #todostimmt das ?)
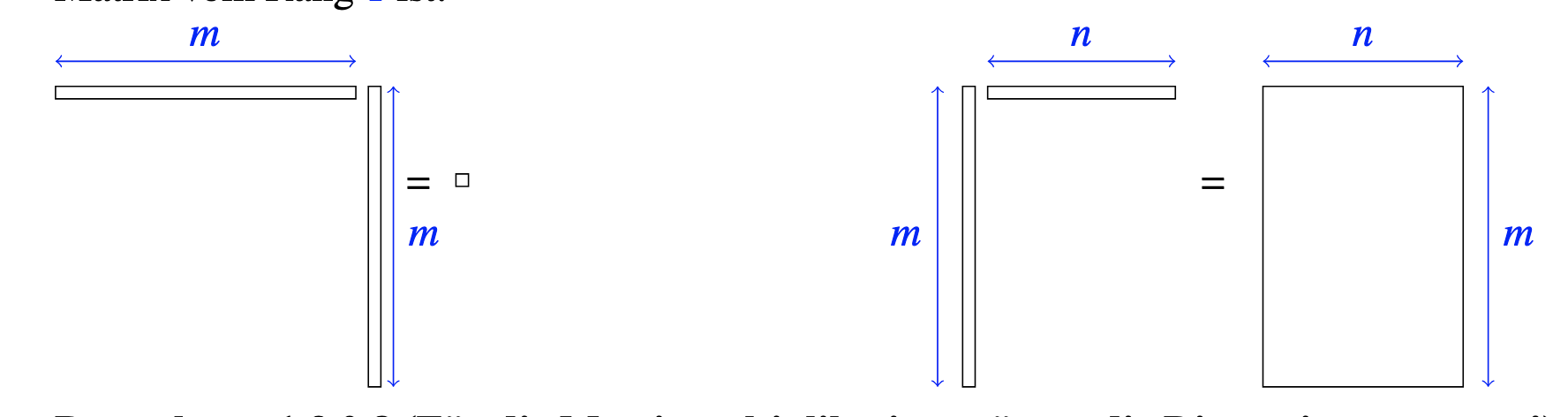
Rang einer Matrix
Der Rang einer Matrix , notiert als , ist die Anzahl der Pivote der Matrix nach der
Gauss-Elimination.
freie Variablen Spalten sind lineare Kombinationen der jeweils vorigen Spalten
Lösungsdiskussion
Rang Anzahl Variablen
Note
Verträglichkeit Kompatibilitätsbedinungen
Verträglichkeit (KB) erfüllt -> genau eine Lösung
nicht erfüllt -> keine Lösung
Verträglichkeit (KB) erfüllt -> unendlich viele Lösungen
nicht erfüllt -> keine Lösung
Alle KB müssen erfüllt sein, damit das LGS mindestens eine Lösung hat
Satz 1.2.0.20.
Für ein lineares Gleichungssystem mit Matrix und gilt:
Falls es eine Lösung gibt, ist diese eindeutig dann und nur dann, wenn .
Homognes LGS
Ein homogenes LGS hat genau dann nicht triviale Lösungen () wenn
Reguläre/Singuläre Matrix
heisst
regulär (voller Rang)
Rang(A) = 𝑟 = 𝑛
Für jedes b gibt es genau eine Lösung
Ax = 0 hat nur x = 0 als Lösung
heisst singulär (nicht voller Rang)
Rang(A) = 𝑟 < 𝑛
Für gewisse b gibt es keine Lösung
Für kein b gibt es eine eindeutige Lösung
Ax = 0 hat nicht triviale Lösungen
1.3 Operation mit Matrizen
(Hermite) transponierte Matrix
für
Zeilen und Spalten werden vertauscht ->
Hermite transponierte Matrix ()
alle einträge werden zu ihren komplex Konjugiereten
Matrixaddition
alle Einträge der Matrizen an gleicher Position werden addiert
Eigenschaften:
kommutativ
assoziativ
ist neutrales Element
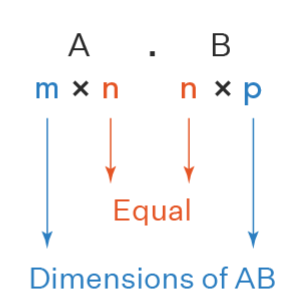
Matrixmultiplikation
Seien
So ist die Multiplikation der Matrix A B die ZUsammenstellung der Multiplikation von mit jedem Spaltenvektor von zu
der Rang von ist der Kleinste Rang der Faktoren
nicht kommutativ
ist ein neutrales Element
Eigenschaften:
assoziativ
distributiv bezüglich ""
spezielle Fälle:
Matrixpotenz
Sei
LGS
Ein lineares Gleichungssystem (LGS) wird kurz geschrieben als:
wobei die Koeffizientenmatrix, die Unbekannte und die rechte Seite ist
Da beliebige Werte auf der Diagonale hat, führen wir ein, welche die Diagonalwerte von auf der Diagonale hat. Ausserdem führen wir ein, sodass
(falls die Diagonaleinträge )
Cholesky-Zerlegung
Zerlegen man in zwei Matrizen
Kombiniert mit der [[#LDU-Zerlegung]]:
Das ist eine obere Dreiecksmatrix
1.7 Orthogonale Matrizen
euklidische Form
die Länge der Matrix
Skalarprodukt
Winkel
Orthogonalität
Zwei Vektoren sind orthogonal, wenn
Eine reelle Matrix heisst orthogonal, wenn
- alle Spalten stehen aufeinander und haben Länge 1.
- Orthogonale Matrizen verändern Länge und Winkel nicht.
Orthogonale Operationen zweier Matrizen
A ist invertierbar,
ist orthogonal
ist orthogonal
ist orthogonal
Bsp:
Drehmatrix
Permutationsmatrizen
Spiegelmatrizen
Drehmatrizen
Matrix, welche einen Vektor um dreht (abbildet).
Um zurückzudrehen, kann man anwenden, oder .
, d.h. die Drehmatrix ist orthogonal.
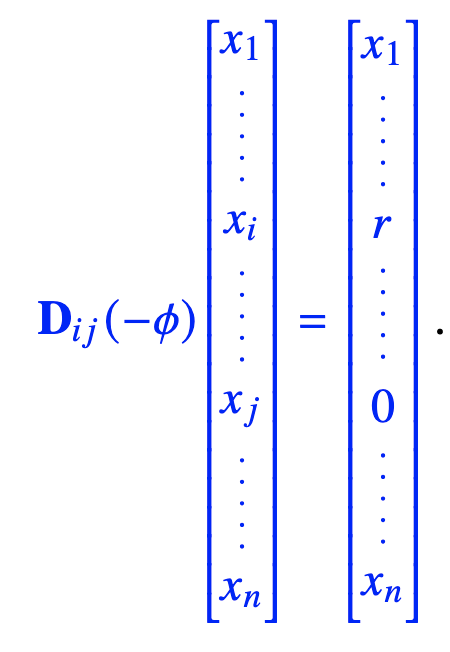
kann für 𝑛 Dimensionen erweitert werden:
Die Matrix, die eine Rotation in der 𝑖- 𝑗 Ebene eines 𝑛 dimensionalen Raumes ausführt, gleicht überall der Identitätsmatrix, ausser in den 𝑖-ten, 𝑗-ten Spalten und Zeilen, in denen die Rotationsmatrix für den zweidimensionalen Raum eingefügt wird.
Dadurch kann eine komplexe Drehung in mehrere einfache Drehungen im 2D-Raum aufgeteilt werden.
Die Drehung in der Ebene ist:
wobei
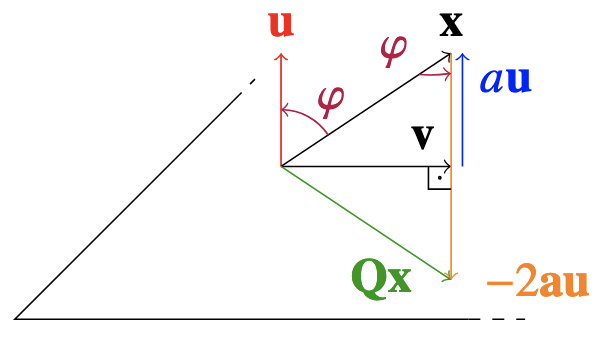
Spiegelung mittels Householder-Matrix
Der Skalar . Mit ihm berechnet ist (und auch alleine)
falls (nicht Norm 1), dann muss mit gerechnet werden.
Die Householder-Matrix ist orthogonal
QR-Zerlegung
Um Rundungsfehler zu vermeiden, braucht es eine neue Zerlegungsart. Die QR-Zerlegung ist die Zerlegung einer Matrix in eine orthogonale Matrix und eine obere
Dreiecksmatrix , so dass .
Dabei muss die Drehmatrix für jede 0 einzeln angewendet werden.
Die Zerlegung mit Spiegelung erzeugt alle Nullen in einer Spalte gleichzeitig.
Ein linearer Raum heisst endlichdimensional wenn es eine endliche Menge gibt, die erzeugend für ist.
sind endlichdimensionale Räume
sind nicht endlichdimensional
2.3 Lineare Unabhängigkeit und Basis
Für linearer Raum, möchten wir die Menge haben, mit der sich alle anderen Elemente erzeugen lassen. Falls sich ein Element durch andere Elemente erzugen lässt, liefert es keine neuen Information, weshalb wir es ausschliessen können.
Def Lineare Unabhängigkeit
Die elemente eines linearen Raumes sind lineare unabhängig, falls
Das gegenteil ist linear abhängig.
Durch die Gauss-elimination lässt sich herausfinden, ob die Spalte n einer Matrix linear (un)abhängig sind. Nur ween der Rang der Matrix voll ist, ist sie linear unabhängig.
Satz 2.3.0.4. Linear unabhängige Spalten einer Matrix
Die Spaltenvektoren einer Matrix sind linear unabhängig genau dann wenn der Rang der Matrix ist.
Def 2.3.0.5 Basis
Eine linear unabhängiges Erzeugendensystem eines linearen Raumes heisst Basis von .
Satz 2.3.0.10. Grösse von erzeugenden Systemen in einem endlichdimensionalen Raum
Sei ein linearer Raum mit Dimension , dann:
sind mehr als Elemente von linear abhängig.
sind weniger als Elemente von nicht erzeugend.
sind Elemente von linear unabhängig genau dann, wenn sie auch erzeugend sind.
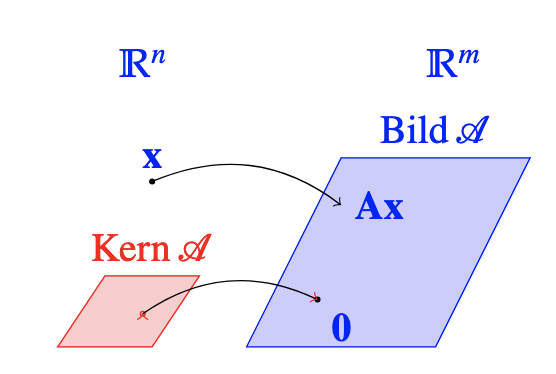
2.4 Fundamentalsatz der linearen Algebra - Teil 1
Satz 2.4.0.1 Basis im Bild A
Sei die LU-Zerlegung der Matrix . Wir notieren die Indizes der Pivotspalten in mit . Die dazugehörigen Spalten aus linear unabhängig. Alle anderen Spalten von A lassen sich als lineare Kombinationen von schreiben, welche somit eine Basis im Bild bilden.
-> Oder: sind linear unabhängig
Bem:
Satz 2.4.0.4 Dimension von Kern A
Sei die Matrix , Matrix von Rang . Dann:
Def 2.4.0.6 Orthogonalität von Unterräumen
Seien und Unterräume von . Wir sagen, dass orthogonal auf stehe, notiert mit , falls beliebige Vektoren aus und aus orthogonal sind (), d.h. mit Skalarprodukt in :
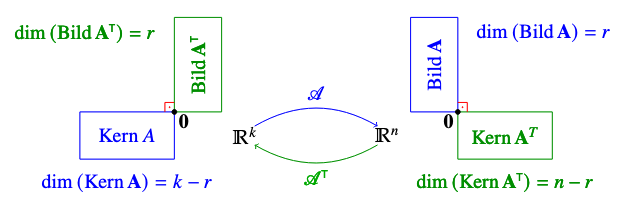
Satz 2.4.0.7 Fundamentalsatz der linaren Algebra - Teil I.
Sie eine Matrix vom Rang . Dann hat die Matrix auch Rang und:
Dimensionen der Unterräume:
Dimensionssatz:
orthogonale Unterräume:
Bem: Zudem kann jedes eindeutig in zwei orthogonale Komponenten zerlegt werden:
Theorem:
Bestimmung von lin. Abhängigkeit
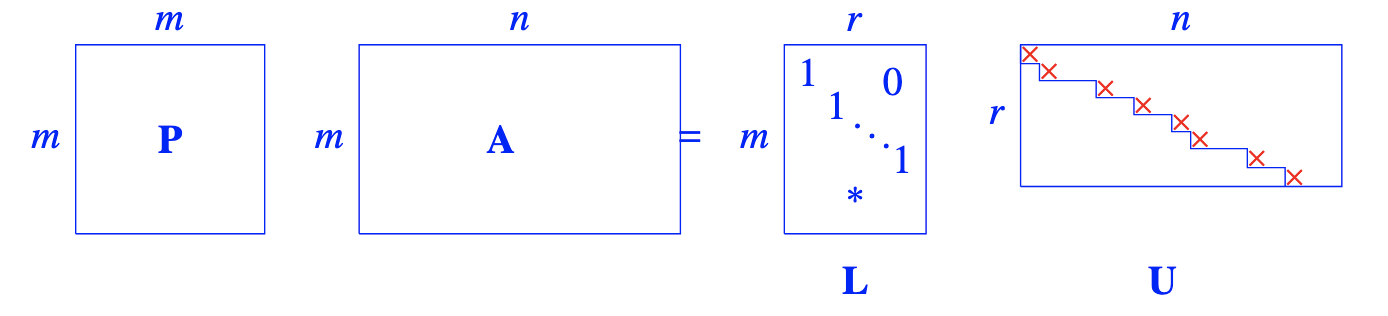
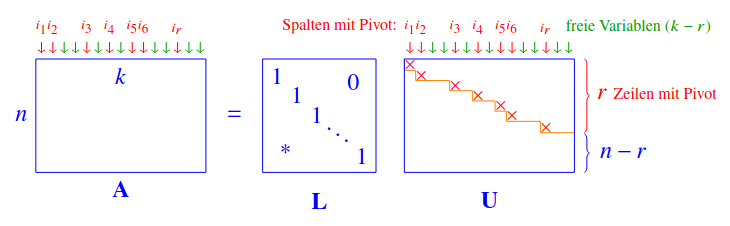
Jede Matrix kann durch Gauss-Elimination (und vertauschung von Zeilen und Spalten) in die folgende Form gebracht werden:
ist dabei die Zeilen-Prozessmatrix, und die Spalten-Prozessmatrix
2.5 Koordinaten und Basiswahl
Satz 2.5.0.1: Jedes element eines linearen Raumes lässt sich als lineare Kombination der Basis von eindeutig darstellen.
Def 2.5.0.2 Koordinatenabbildung und Koordinaten
Sei ein linearer raum mit , dessen Basis
ust die Koordinatenabbildung in der Basis , sind die Koordinaten von inder Basis .
#todo Beispiele in Aufschrieb W5, letzte zwei Seiten
3 Lineare Abbildungen
Def 3.1.0.1 Lineare Abbildung
lineare Räme, ist linear, falls
für alle
für , Skalar
-> ein linearer raum ist abgeschlossen unter Addition und Multiplikation
Bem Bei Aufgaben mit Isomorphismen/Automorphismen erkennen muss man vor allem (einzig) die Dimensionen anschauen!
4 Norm und Skalarprodukt in linearen Räumen
4.1 Normierte lineare Räume
Def 4.1.0.1. Norm
Sei 𝑉 ein linearer Raum. Die Funktion heisst Norm in 𝑉, falls sie folgende Eigenschaften erfüllt:
Aus folgt .
-> Der Einzige Vektor von Länge is der Nullvektor
Sei ein Skalar und beliebig. Dann gilt: .
Für beliebige gilt: (Dreiecksungleichung).
Def 4.1.0.2 Normierte Lineare Räume
Ein linearer Raum , welcher eine Norm besitzt, heisst normierter linearer Raum
Bsp
euklidische Norm:
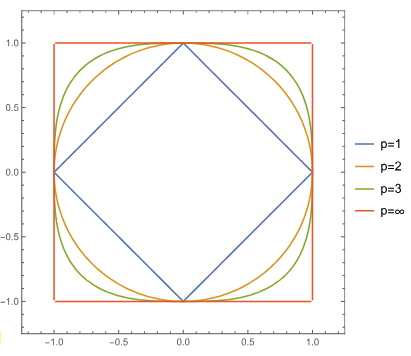
Normen in : fest:
Norm in L::
Die Bedeutung der Norm eines Vektors ist die Länge. Ein Ball sieht in den verschiedenen Normen anders aus, weil die jede Norm eine andere Länge des Vektors hat:
Alle Normen in sind äquivalent. In anderen Worten:
Seien und Normen in , dann gibt es eine Konstante , abhängig von der Dimension , so dass
Def 4.1.0.8 Matrixnorm aus der Vektornorm
DIe Vektornorm in induziert im linearen Raum der Matrizen eine Norm:
Bsp Matrixnormen:
Zeilensummen-Norm (maximum der Zeilensumme):
Spaltensummen-Norm (maximum der Spaltensumme):
Frobenius-Norm (wurzel der diagonalquadrate):
Spektralnorm ( ist der grösste Eigenwert von ):
4.2 Skalarprodukt in linearen Räumen
Def 4.2.0.1 Skalarprodukt
Sei ein inearer Raum.
EIn Skalarprodukt ist eine FUnktion von zwei Variablen in diesem Raum
welche die folgenden drei Eigneschaften erfüllt.:
Die funktion ist linear im zweiten Argument:
für alle und Skalare
2. Die Funktion ist Symmetrisch:
Die funktion ist positiv definit:
falls von (3) nur ein punkt erfüllt ist positiv semi-definit
Def 4.2.0.4 Norm aus einem Skalarprodukt
Man sagt, dass eine Norm aus einem Skalarprodukt kommt, falls
für alle Elemente eines linearen Raumes .
Def 4.2.0.5 Orthogonalität von Elementen eines linearen Raumes mit Skalarprodukt
Sei , wobei ein linearer Raum mit einem Skalarprodukt ist. Wir sagen, dass und orthogonal sind, falls
Bsp: A-Skalarprodukt
wobei , eine Diagonalmatrix ohne in der Diagonale und eine orhogonale quadratische Matrix.
Orthogonale Projektionen
Bem: Siehe Def 4.2.0.5 für orthogonalität
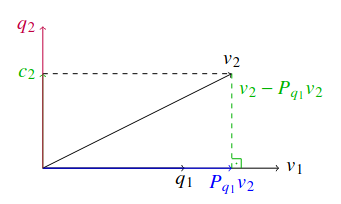
Def 4.2.0.9 Orthogonale Projektion auf einen Vektor
Sei ein linearer Raum mit einem Skalarprodukt . So ist die orhogonale Projekiton von x auf , für , definiert als
Bem:
Satz 4.2.0.11 Schwarz'sche Ungleichung
Sei ein linearer Raum mit einem Skalarprodukt , dann gilt folgende Ungleichung für alle Elemente :
Dies kann alternativ auch mit der aus dem Skalarprodukt kommenden Norm geschrieben werden:
2.0.12 Winkel in einem linearen Raum
Der Winkel zwischen zwei Elementen 𝑥 und 𝑦 eines linearen Raumes 𝑉 mit Skalarprodukt ist definiert als
Satz 4.2.0.13. Pythagoras
Sei ein linearer Raum mit Skalarprodukt und einer aus diesem Skalarprodukt kommende Norm .
Für zwei Elemente 𝑥 und 𝑦, welche orthogonal aufeinander stehen (), gilt
Einheitsvektor und orthonormale Basen
Def. 4.2.0.14 Einheitsvektor
Sei , mit ein linearer Raum mit der Norm . Falls , heisst Einheitsvektor.
Satz 4.2.0.15 Orthogonale Vektoren sind linear unabhängig
Seien Einheitsvektoren in einem linearen Raum 𝑉 mit einer Norm , die aus dem Skalarprodukt kommt.
Falls die Einheitsvektoren paarweise orthogonal sind, so sind sie auch linear unabhängig.
Als direkte Konsequenz davon:
Satz 4.2.0.16 Orthonormale Basis
paarweise orthogonale Einheitsvektoren in einem linearen Raum der Dimension bilden eine orthonormale Basis in diesem Raum.
Bem 4.2.0.17 (Berechnung der Koordinaten in einer orthonormalen Basis) #todo aufschreiben
Bem 4.2.0.19 (Projektoren auf die Elemente einer orthonormalen Basis)
Satz 4.2.0.20 Parseval
Das Skalarprodukt in lässt sich über das euklidischen Skalarprodukt in berechnen:
Bem 4.2.0.21 (Projektion auf einen Unterraum) #todo fertigschreiben
4.3 Gram-Schmidt-Algorithmus
Satz 4.3.0.1. Gram-Schmidt
Wenn 𝑉 ein linearer Raum mit Basis und Skalarprodukt ist, dann gibt es eine orthonormale Basis (ONB) für , so dass für ist.
d.h.
ein endlich-dimensionaler Raum besitzt immer eine orthonormale Basis
die orthogonalen Vektoren bilden verschachtelte Räume
#todo: Der Beweis zum Gram-Schmidt-Algorithmus zeigt, wie man orthogonale Vektoren berechnet -> anschauen
Beweis
Bedignungen für sind, dass es Norm 1 haben muss, und den gleichen Unterraum wie aufspannen muss, d.h.
Nun für :
Und so auch für :
QR-Zerlegung mittels Gram-Schmidt
Sei eine Matrix mit der Basis . Dann können wir als lineare Kombination schreiben:
Für alle Elemente in der Basis können wir dann schreiben:
Dann ist , wobei orthogonal und obere Dreiecksmatrix.
Vorzeitiges Ende des Gram-Schmidt-Algorithmus
Falls , bricht der ganze Algorithmus zusammen, weil eine lineare Kombination von nicht linear abhängig ist.
-> weg, um lineare Unabhängigkeit einfach zu überprüfen
Bem:
Bei numerischen Berechnungen hat Gram-Schmidt ab erhebliche Rundungsfehler (float). Es gibt einen modifizierten Gram-Schmid-Algorithmus, bei dem der Rundungsfehler nur linear zunimmt.
4.4 Projektoren
Aus Kapitel 4.2 wissen wir, was ein orhogonaler Projektor ist:
Den wir als Matrix schreiben können, falls der lineare Raum oder :
Def 4.4.0.1. Projektor
Sei 𝑉 ein linearer Raum. Eine lineare Abbildung heisst Projektor falls
Def 4.4.0.2. Orthogonale und schiefe Projektoren
Der Projektor im linearen Raum 𝑉 mit dem Skalarprodukt heisst orthogonaler Projektor, falls
sonst heisst er schiefer Projektor.
Satz 4.4.0.3. Orthogonale und schiefe Projektoren
Der Projektor im linearen Raum mit dem Skalarprodukt ist ein orthogonaler Projektor genau dann, wenn
d.h. wenn der Projektor ein selbstadjungierter Operator ist.
Satz 4.4.0.4. Orthogonale und schiefe Projektoren
Die Matrix ist ein orthogonaler Projektor genau dann, wenn
Falls nur die Bedingung erfüllt ist, so ist ein schiefer Projektor.
Bsp #todo anschauen, wie man skizze von schiefem Projektor aussieht
Def 4.4.0.7. Orthogonaler Projektor auf einen Unterraum
Sei eine Matrix mit orthogonalen Spaltenvektoren welche Norm haben. Der orthogonale Projektor welche auf den Unterraum projiziert ist
die folgenden Definition wurden nicht behandelt:
Def 4.4.0.7. Orthogonaler Projektor auf einen Unterraum
Sei eine Matrix mit orthogonalen Spaltenvektoren welche Norm 1 haben. Der orthogonale Projektor welche auf den Unterraum projiziert ist
Def 4.4.0.9. Schiefer Projektor auf einen Unterraum
Wenn und zwei Matrizen mit der Eigenschaft sind, dann kann ein schiefer Projektor , welcher auf den Unterraum der Spaltenvektoren von projiziert, definiert werden als
Zusatz: Lineares Funktional
Lineares Funktional
Sei lin. Raum über . Das lineare Funktional ist dann
Bsp ,
Theorem (Riesz)
, dim . Sei ein lineares Funktional.
Es gibt ein eindeutiges sodass für alle
Sei ONB in . Dann
-> hängt nicht von der Wahl der Basis ab, da es dann nicht eindeutig wäre
Bsp
ONB:
#todo andere Beispiele im Aufschrieb Woche 8 anschauen
Zusatz: Die adjungierte Abbildung
Seien , lineare Räume über mit s.p.
Def adjurgierte Abbildung
ist die adjungierte Abbildung einer Abbildung , wenn
für alle ,
Bem und für alle , dann
Konsequenz: lin. Abbildung
=> es gibt maximal eine adj. Abbildung!
Das LGS aus 5.1 kann folgendermassen mit der Normalengleichung gelöst werden.
Def 5.2.0.1 Normalengleichung
Satz 5.2.0.2. Lösung der Ausgleichsrechnung mit der Normalengleichung
Sei eine Matrix gegeben. Falls der Rang dieser Matrix gleich ist, so ist invertierbar.
In diesem Fall hat die Normalengleichung also genau eine Lösung, die die Lösung des linearen Ausgleichsproblems ist.
Probleme mit der Normalengleichung
normalerweise stimmt nicht -> Normalengleichung nicht anwendbar
Falls Spalten/Zeilen numerisch abhängig sind, gibt es grosse Fehler im Ergebnis
-> Stattdessen wird normalerweise die Singulärwertszerlegung benutzt #todo link einfügen
5.3 Lösung mit der QR-Zerlegung
Alternativ zur Normalengleichung kann man die QR-Zerlegung verwenden:
Wenn Rang hat, hat gleichen Rang -> ist invertierbare obere Dreiecksmatrix mit ersten Zeilen. Q ist orthogonal, . Dann haben wir:
Seien 𝑉 und 𝑊 zwei lineare Räume. ist eine lineare Abbildung falls . ist eine bilineare Abbildung falls linear in jedem der beiden Argumente ist. ist eine multilineare Abbildung falls linear in jedem Argument ist.
Def 6.1.0.3 Determinante
Die Determinante ist eine Funktion
mit folgenden Eigenschaften
(D1)
(D2) wechselt das Vorzeichen, wenn zwei Zeilen oder Spalten vertauscht werden (Antisymmetrie)
(D3) ist linear in jeder Zeile und Spalte:
Bem
beschreibt eine eindeutige Abbildung
In der Praxis ist die Def. schwierig anwendbar, aber wir können folgende Eigenschaften daraus herleiten:
zwei Spalten/Zeilen von identisch
lin.Komb. von Zeilen von Matrix ändern die Determinante dieser Matrix nicht.
hat Nullzeilen/Nullspalten
Dreiecksmatrix ist Produkt der Diagonaleinträge
singulär (keine Inverse #todo überprüfen) durch Gauss-elimination entsteht Nullzeile wegen (6)
wenn A inv.bar
Entwicklung der ersten Zeile:
wächst exponentionell für -> Gauss-elimination wächst schlimmstenfalls mit -> Eigenschaft nur für Handrechung gedacht (oder Theorie)
Bsp
Determinante mit Gauss berechnen
Sei die obere/untere Diagonalmatrix, die mit Gauss-elimination aus hervorgeht.
Dann ist das Produkt der Diagonaleinträge =
ist wegen möglich
vertauschen von Zeilen/Spalten wechselt das Vorzeigen
7 Eigenwerte
7.1 Motivation
emptiness
7.2 Eigenwerte und Eigenvektoren
Bem In diesem Kapitel arbeiten wir mit (quadratischen) Matrizen.
Sei ein linearer Raum und lineare Abbildung.
Def 7.2.0.2. Eigenwertproblem
heisst Eigenwert der Matrix , falls es ein gibt, sodass . heisst dann Eigenvektor von zum Eigenwert .
diagonalisierbar falls es gibt invertierbar sodass
Satz 7.2.0.3. Wenn eine Matrix diagonalisierbar ist, dann sind die Elemente auf der Diagonale von Eigenwerte und die Spalten von sind die entsprechenden Eigenvektoren.
Def. 7.1.0.5 Ähnlichkeit
Zwei Matrizen sind ähnlich, falls eine invertierbare Matrix existiert, sodass
Bem 7.3.0.2 Strukturierte Matrizen, spezielle Eigenwerte
Die Menge der Eigenwerte hängt vom Verhältnis zwischen und ab:
-> auch bei diesen Matrizen sind die Eigenvektoren orthogonal zueinander.
Definition 7.3.0.3. Normale Matrix
Satz 7.3.0.5
hat orthogonale Eigenvektoren normal
Satz 7.3.0.6 Spektralsatz
Jede symmetrische Matrix lässt sich durch orthogonale Transformationen diagonalisieren.
-> es gibt eine orthogonale (unitäre) Matrix und eine diagonale Matrix , sodass
Bemerkung 7.3.0.7 (Normale Matrizen sind Summen von unitären/orthogonalen Projektoren)
Sei eine symmetrische (normale) Matrix. Dann lässt sie sich wegen dem Spektralsatz durch unitäre/orthogonale Transformationen diagonalisieren:
dann
Bemerkung 7.3.0.8 (Diagonalisierbare Matrizen sind Summen von (schiefen) Projektoren)
Falls eine matrix nur diagonalisierbar ist:
das heisst auch ( ist ein schiefer Projektor, nicht orthogonal):
Bem
gilt nicht, falls normal, aber nicht symmetrisch
Optimierung für symmetrische Matrizen
Satz 7.3.0.9. Euklidische Norm und Eigenwerte
Satz 7.3.0.10. Die Eigenwerte der inversen Matrix
Der kleinste EW von / ist strikt positiv.
Definition 7.3.0.11. Konditionszahl
Die Konditionszahl einer invertierbaren Matrix ist
Die Konditionszahl einer invertierbaren, symmetrischen Matrix ist
wobei grösster EW, kleinnster EW von
Bem #todo Vorlesung Anschauen; Aufschrieb unleserlich
symmetrische Matrix ist positiv-definit ale EW strikt positiv
Bem
Eine spd Matrix ergibt:
Bem 7.4.0.6 (S.p.d.-Test via Pivote.)
Wenn die Gauss-Elimination einer symmetrischen, quadratischen Matrix (strikt) positive Pivote hat, dann ist die Matrix positiv definit.